






How Gemma 4’s E2B, E4B, 26B, and 31B Variants Deliver On-Device Reasoning, Coding, Vision, and Agentic AI Across RTX PCs, DGX Spark, and Jetson Edge Devices
The release of Google’s Gemma 4 family marks a decisive inflection point in the trajectory of open, locally-executable AI models. Where previous generations of small language models traded capability for compactness, Gemma 4 delivers genuine multimodal intelligence — spanning text, images, video, and audio — across a parameter range that spans ultralight edge deployments at 2 billion parameters all the way to production-grade agentic workloads at 31 billion parameters.
When paired with NVIDIA GPU infrastructure, from consumer RTX graphics cards through the DGX Spark personal AI supercomputer to Jetson Orin Nano edge modules, these models achieve the throughput and latency characteristics required for real-world, always-on AI applications that operate without cloud dependency.
WHAT IS GEMMA 4?
Gemma 4 is Google’s fourth-generation family of open-weight language and multimodal models, designed explicitly for efficient local execution across a diverse range of compute platforms. Unlike proprietary cloud-only models, Gemma 4 weights are openly available, enabling organizations and individual developers to download, deploy, fine-tune, and integrate these models without API rate limits, cloud data transmission requirements, or per-token billing.
1. Native Multimodality Across Text, Images, Video, and Audio
Gemma 4 models are not text-only systems with bolt-on vision adapters. The multimodal architecture is trained end-to-end to process interleaved sequences of text and image tokens in arbitrary order within a single prompt context. This enables applications that reason across documents containing mixed text and visual content, analyze screenshots alongside natural language instructions, or process video frames with temporal reasoning.
2. Ultraefficient Edge Variants (E2B and E4B)
The E2B (2-billion parameter) and E4B (4-billion parameter) variants are engineered specifically for constrained compute environments, including NVIDIA Jetson Orin Nano edge AI modules and consumer-grade hardware. These models operate completely offline with near-zero latency, making them viable for embedded applications in robotics, industrial vision, smart home devices, and autonomous systems.
3. High-Performance Reasoning and Agentic Variants (26B and 31B)
The 26B and 31B parameter models deliver state-of-the-art reasoning quality for developer-centric workflows, coding assistance, and agentic task automation. These models are optimized for NVIDIA RTX GPU deployment and the DGX Spark personal AI supercomputer, where Tensor Core acceleration provides the throughput necessary for interactive, real-time agentic applications.
4. Broad Multilingual Coverage
Gemma 4 is pretrained on data spanning more than 140 languages, with out-of-the-box inference quality across 35+ languages. This makes the model family immediately deployable for global enterprise applications without language-specific fine-tuning.
GEMMA 4 MODEL VARIANTS: CAPABILITY & HARDWARE REQUIREMENTS
Gemma 4 E2B — Ultraefficient Edge Intelligence (2B Parameters)
Optimized for maximum efficiency at minimum parameter count. At 2 billion parameters quantized to Q4_K_M format, E2B fits within the memory constraints of edge devices including NVIDIA Jetson Orin Nano modules with 8GB of unified memory.
Target hardware: Jetson Orin Nano (8GB/16GB), RTX 30/40/50-series GPUs with 8GB+ VRAM, CPU-only via llama.cpp
Use cases: Always-on background AI inference, keyword detection, real-time translation, voice-to-action pipelines in embedded robotics, and local AI features in mobile-adjacent developer tooling.
Gemma 4 E4B — Balanced Edge AI (4B Parameters)
Expands the E2B’s capability envelope with additional parameters for reasoning depth and instruction-following fidelity, while remaining within the memory budget of consumer hardware.
Target hardware: Jetson Orin Nano (16GB), Jetson Orin NX, RTX 30-series with 12GB+, RTX 40/50-series GPUs
Use cases: Local coding assistants, document intelligence, structured data extraction, conversational AI with sustained multi-turn context.
Gemma 4 26B — Production Agentic AI
The first model in the family designed primarily for agentic AI workflows — applications where the model must autonomously plan and execute multi-step tasks using tool calls, file system access, API interactions, and feedback loops. Native support for structured tool use (function calling) enables iterative task completion.
Target hardware: RTX 4090 (24GB VRAM at Q4_K_M), RTX 5090 (32GB), RTX A6000 Ada (48GB), DGX Spark (128GB)
Use cases: Local agentic AI assistants, automated software development, code review pipelines, long-context document analysis, multi-step research automation.
Gemma 4 31B — Maximum Capability Open Model
The highest-capability configuration, delivering state-of-the-art reasoning, coding, and multimodal performance among openly available models at its parameter scale.
Target hardware: RTX 5090 (32GB at Q4_K_M), RTX 6000 Ada (48GB), DGX Spark (128GB at full precision), multi-GPU RTX setups
Use cases: High-quality code generation, advanced reasoning for research, sophisticated agentic pipelines, enterprise document intelligence.
GOOGLE & NVIDIA COLLABORATION: GPU OPTIMIZATION
NVIDIA Tensor Core Acceleration
NVIDIA’s Tensor Cores — specialized matrix multiplication units present in every RTX GPU from Turing through Blackwell — are architecturally aligned with the core computational primitive of transformer inference: the GEMM (General Matrix Multiply) operation. Every attention computation and feed-forward layer maps directly onto Tensor Core execution.
At Q4_K_M quantization, the inference engine represents model weights in 4-bit integers with block-wise scaling factors, enabling Tensor Cores to operate at maximum throughput by fitting larger working sets into VRAM and reducing memory bandwidth pressure.
CUDA Software Stack: Day-One Compatibility
NVIDIA’s CUDA ecosystem provides a stable abstraction layer that enables inference frameworks — including llama.cpp, Ollama, and Unsloth — to target NVIDIA GPU hardware without model-specific optimization. When Google releases a new Gemma 4 variant, CUDA-based frameworks can immediately load and execute it on any supported NVIDIA GPU without driver updates or hardware-specific kernel tuning.
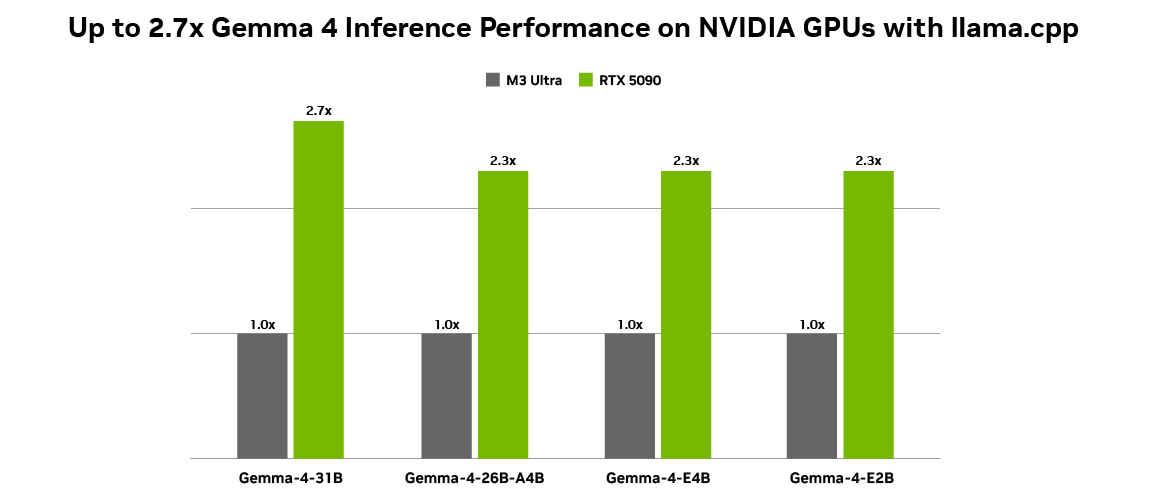
HOW TO RUN GEMMA 4 LOCALLY ON NVIDIA RTX GPUs
Method 1: Ollama — Fastest Path to Local Inference
Ollama provides a single-command experience for downloading and serving any Gemma 4 variant. With CUDA drivers installed, Ollama automatically detects the GPU and allocates model layers to VRAM.
curl -fsSL https://ollama.com/install.sh | sh
# Pull and run Gemma 4 E4B (recommended for most RTX GPUs)
ollama run gemma4:4b
# Pull and run Gemma 4 27B (for RTX 4090 / RTX 5090 / DGX Spark)
ollama run gemma4:27b
# Run with multimodal input (image + text)
ollama run gemma4:27b "Describe this image" --image /path/to/image.jpg
Ollama’s OpenAI-compatible API endpoint means any application built against the OpenAI Python SDK can be redirected to a local Gemma 4 instance by changing the base_url parameter — zero code changes required.
Method 2: llama.cpp — Maximum Performance Control
llama.cpp provides the most granular control over inference performance parameters, quantization format selection, and hardware utilization.
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Release -j$(nproc)
# Download Gemma 4 GGUF checkpoint from Hugging Face
huggingface-cli download google/gemma-4-27b-it-GGUF \
gemma-4-27b-it-Q4_K_M.gguf --local-dir ./models/gemma4-27b
# Run inference with full GPU offloading
./build/bin/llama-cli \
-m ./models/gemma4-27b/gemma-4-27b-it-Q4_K_M.gguf \
-ngl 99 -c 8192 \
-p "Write a production-ready REST API in Python"
The -ngl 99 flag offloads all transformer layers to GPU VRAM. For GPUs with insufficient VRAM, reducing this value offloads remaining layers to CPU RAM automatically.
Method 3: Unsloth Studio — Fine-Tuning and Optimized Deployment
Unsloth provides day-one Gemma 4 support with optimized quantized model variants and a fine-tuning pipeline that enables parameter-efficient adaptation on consumer RTX hardware. Unsloth’s gradient checkpointing reduces VRAM consumption during fine-tuning by approximately 60%, enabling fine-tuning of the Gemma 4 26B model on a single RTX 4090 with 24GB VRAM using LoRA adapters.
GEMMA 4 MULTIMODAL CAPABILITIES
Interleaved Multimodal Input
Gemma 4 processes interleaved sequences where image tokens and text tokens appear in any order within the same context window, enabling prompts such as:
- “Here is the error message [image]. Now look at the code [image]. Explain the root cause and provide a fix.”
- “Compare these two architectural diagrams [image 1] [image 2] and identify differences.”
- “This is the UI mockup [image]. Write React component code that implements this layout.”
Video Understanding and Temporal Reasoning
Gemma 4’s video comprehension enables processing sequences of video frames with temporal reasoning — identifying events over time, tracking object state changes, and answering causal relationship questions. Applications include security analysis, manufacturing quality inspection, sports analysis, and content indexing.
Automated Speech Recognition (ASR)
Audio capabilities include automated speech recognition, enabling the model to process voice input alongside text and visual context. Particularly significant for agentic AI applications where the user interaction modality is voice.
AGENTIC AI ON NVIDIA RTX
OpenClaw: Local Agentic AI on RTX GPUs
OpenClaw is NVIDIA’s framework for building always-on local AI agents on RTX PCs, workstations, and DGX Spark. The Gemma 4 26B and 31B models are fully compatible, providing the reasoning quality and function-calling reliability required for practical agentic task automation. An OpenClaw agent powered by Gemma 4 can:
- Monitor active application context and proactively suggest relevant actions
- Execute file system operations based on natural language instructions
- Interface with productivity applications via defined tool schemas
- Chain multiple tool calls across extended reasoning sequences
- Maintain conversation history and task state across sessions
NVIDIA NemoClaw: Security-Hardened Agent Stack
NemoClaw extends OpenClaw with an open source architecture that prioritizes security for agentic AI systems. Key features include sandboxed tool execution, local model enforcement (blocking cloud inference routes), audit logging, and role-based tool permissions.
CHOOSING THE RIGHT GEMMA 4 VARIANT
| Requirement | Variant | Hardware Minimum |
|---|---|---|
| Offline edge AI, IoT, robotics | E2B | Jetson Orin Nano 8GB |
| Enhanced edge reasoning, coding | E4B | Jetson Orin NX / RTX 8GB |
| Local agentic AI, dev workflows | 26B | RTX 4090 24GB |
| Maximum quality, production agentic | 31B | RTX 5090 32GB / DGX Spark |
| Multi-model serving, full precision | 26B + 31B | DGX Spark 128GB |
What This Means for Your Build
If you’re building a PC for local AI workloads, the GPU is everything. An RTX 4090 with 24GB VRAM runs the 26B model comfortably. An RTX 5090 with 32GB VRAM unlocks the full 31B model. Every Lone Star build with an NVIDIA RTX GPU is ready for local AI inference out of the box.
PRIVACY & DATA SOVEREIGNTY: THE CASE FOR LOCAL AI
Running Gemma 4 locally on NVIDIA RTX hardware — without any data leaving the device — addresses privacy requirements that cloud AI services fundamentally cannot satisfy:
- Regulated data environments: Healthcare (HIPAA), financial (GLBA), and legal organizations that cannot transmit sensitive data to cloud AI services.
- Intellectual property protection: Engineering and technology organizations whose proprietary knowledge would be transmitted to third-party infrastructure via cloud API calls.
- Air-gapped deployments: Defense, intelligence, and critical infrastructure operations on networks with no external connectivity.
- Latency-critical applications: Any application requiring sub-100ms inference latency — real-time voice interfaces, interactive coding, live translation — is fundamentally constrained by cloud round-trip times. Local inference eliminates this floor.
THE BOTTOM LINE
The Gemma 4 family establishes a new capability benchmark for open, locally-executable AI models. By spanning from the 2-billion parameter E2B edge variant through the 31-billion parameter production-grade reasoning model, Gemma 4 covers the complete spectrum of local AI inference requirements — from always-on background intelligence on Jetson Orin edge modules to sophisticated agentic workflows on NVIDIA RTX workstations and DGX Spark.
The Google and NVIDIA collaboration ensures that these capability advances are immediately accessible to every developer and organization with NVIDIA GPU hardware, with day-one framework compatibility across Ollama, llama.cpp, and Unsloth. For organizations evaluating the transition from cloud AI dependency to on-device intelligence, Gemma 4 on NVIDIA RTX represents the most capable and accessible local AI deployment path available today.
BUILD FOR LOCAL AI
Our builds feature NVIDIA RTX GPUs with the VRAM and Tensor Core performance required for local AI inference. Configure your AI-ready rig today.
VIEW ALL BUILDS BUILD YOUR OWN